What spaCy thinks of ICAME47: Five Days, Five Clouds
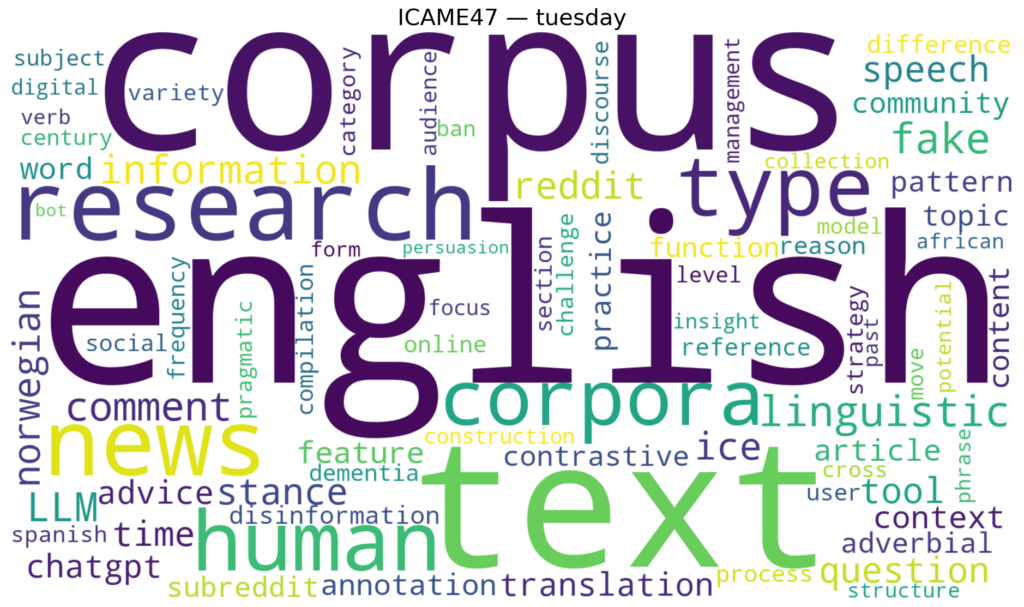
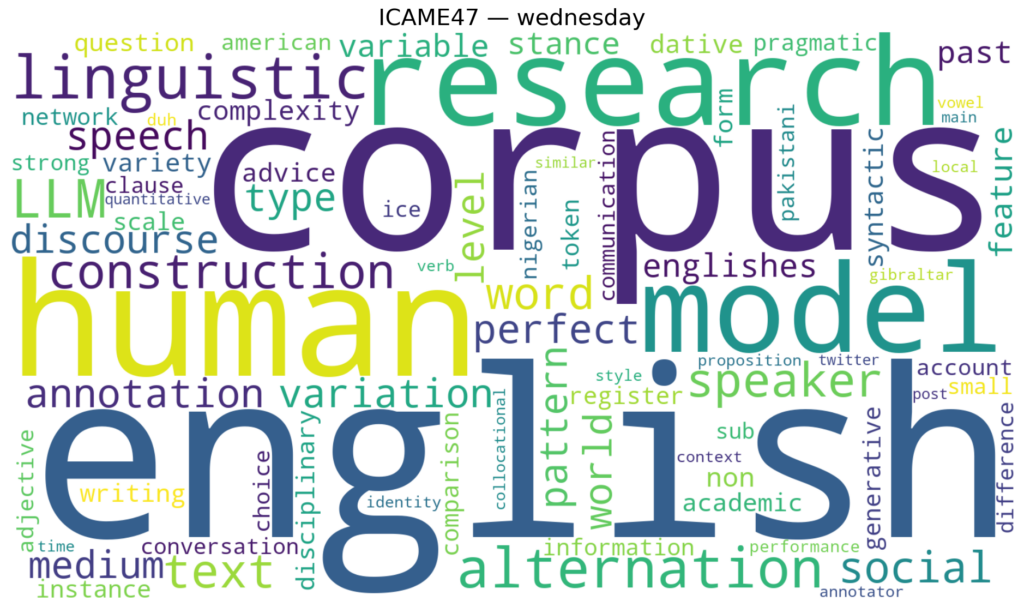

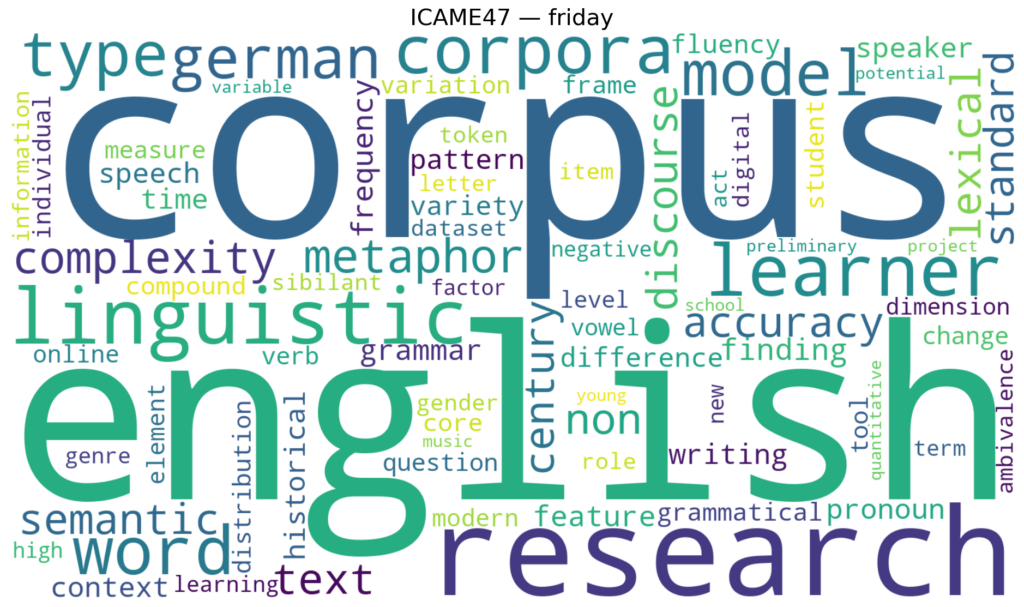
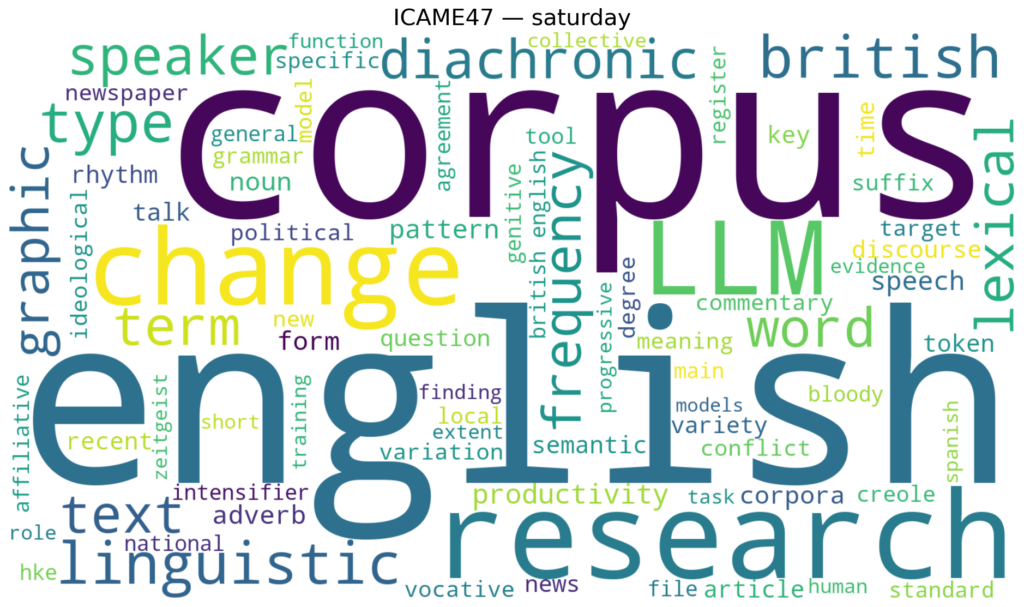
Here’s what ICAME47 sounded like when visualized. The week’s word clouds, one per day, capture the conversations as they unfolded.

Here’s what ICAME47 sounded like when visualized. The week’s word clouds, one per day, capture the conversations as they unfolded.


Among the many highlights of ICAME47 has been the presence of researchers from the University of Oxford, bringing with them the distinctive perspective of one of the world’s most storied institutions. Martin Wynne (Oxford Text Archive) contributed both a workshop and a poster, marking a particularly special moment: the Oxford Text Archive celebrates its own 50th anniversary in 2026. His talks traced fifty years of curating digital language resources — from the early days of the Oxford Concordance Programme and the launch of the Text Encoding Initiative, through the construction of the British National Corpus, to today’s repository of more than 70,000 items — while looking ahead to the opportunities and challenges that AI brings for trusted, authentic language data.
Equally fascinating was Xingni Li‘s poster on speech prosody and rap flows in American English and Cantonese — a cross-linguistic study examining how the rhythmic and tonal features of two very different languages shape their respective rap traditions, and how Cantonese rap appears to be drifting toward the conventions of American English rap. A refreshingly novel topic for a corpus linguistics conference, and a reminder of just how far the field’s methods can travel.
It has been wonderful to have Oxford represented so richly at ICAME47, and we thank Martin and Xingni for their thoughtful contributions.
Our second plenary kicked off the morning with Jonathan Culpeper taking us on a corpus-based journey through Shakespeare’s language – and beyond. Among other things, he set the record straight on how many words Shakespeare invented. Shakespeare invented fewer words than we’ve long been led to believe.
We then celebrated the 50th birthday of the open-access ICAME Journal. Happy birthday! 🎂



Right after, our poster lighting talks got underway: researchers first pitched their projects to the full audience in the lecture hello before the conversation continued over coffee in the foyer. A wonderful mix of perspectives — from senior researchers to a PhD project and even a Master’s student. A reminder that ICAME truly brings together all the days of the research journey. 🌟



On the first official conference day, our social programme kicked off with a stable car ride over the Rhine before a short walk to the coupling room, which rewarded us with a breathtaking view over the Confluence of Rhine and Moselle — the very confluentes that give this year’s conference its name. Good flow continued into the evening with sparkling wine, delicious finger food, and great music. 🥂🎶


The main conference programme of ICAME47 opened on 27th May with a captivating one-hour plenary by one of the most celebrated figures in corpus linguistics, Professor Laurence Anthony of Waseda University. Speaking on “Advancing Corpus Linguistics with Small, Local and Multimodal AI Language Models,” he explored how generative AI and modern language models can be brought together with established corpus linguistic methods to open up new avenues of analysis. Professor Anthony, who holds the National Prize of the Japan Association for English Corpus Studies and is best known worldwide for his AntConc software, kept the audience thoroughly engaged throughout. The highlight was a series of live demonstrations in which he used AntConc to analyse multimodal corpora, integrating large language models and other AI tools to show how they can complement the work of a corpus linguist. It was an inspiring and fitting start to the main conference, leaving participants with much to reflect on as the days unfold.
After a full day of pre-conference workshops yesterday, our welcoming session opened with words from University President Prof. Dr. Wehner and Faculty 2 Dean Prof. Dr. Neuhaus, before JProf. Andreas Weilinghoff got things officially flowing 🌊









We then dove straight into the deep end with our first plenary talk by Laurence Anthony, exploring this year’s conference motto ‘Confluentes’ — where AI and corpus linguistics meet. While corpus linguistics and generative AI share deep roots, they diverge significantly in how they handle data, interaction, and transparency. Anthony made a compelling case for how integrating AI into established corpus tools like AntConc (which he developed) can bridge that gap, opening new possibilities for multimodal analysis while keeping transparency and validity in focus.
Day 1 is off to a great start – more to come!
It was 32°C here in Koblenz today — but the heat couldn’t beat the spirits of our linguists and researchers. Gathered in the Mensa Garten over pretzels and coffee, participants kept the conversation lively, with plenty of discussion on LLMs, AI, and corpus linguistics. The only ‘ICE’ in sight was the corpus kind — though no one seemed to mind. A warm day, in every sense, and a wonderful one.


Just by the Foyer, near to our reception desk, you’ll find a small stall from John Benjamins Publishing Company (website) . Do stop by to browse a selection of titles in linguistics and corpus research. Conference participants can take advantage of special discounts, and authors interested in publishing with John Benjamins are welcome to drop by for more information. The stall is open throughout the conference — visit between the sessions!

ICAME47 had a wonderful start today, with 5 parallel workshops that attracted tremendous interest among the participants. As the conference theme itself is ‘A Confluence of Corpus Research in the Age of AI,’ workshop papers on the use of AI and LLMs in corpus linguistics saw great turnouts. The workshop on “Corpus and Computational Linguistics meet Fake News, Mis- and Disinformation and LLMs” drew particular attention, with papers exploring ‘stance expressions’ in AI-generated versus human-written fake news, whether LLMs can be deceived into trusting disinformation, and the use of LLM agents to test interventions in online echo chambers. Equally well attended was “Data Management, Corpora and AI,” featuring talks that included fifty years of the Oxford Text Archive, Automatic Speech Recognition and the annotation of large multimodal corpora. Workshops on “ICE Corpora in the Age of AI” and “A Confluence of Languages through Corpus-based Contrastive Research in the Age of AI” rounded off a stimulating first day. We look forward to the remaining days of the conference!
The 47th ICAME international conference has started today (26th May, 2026) at the University of Koblenz, Germany. ICAME (International Computer Archive of Modern and Medieval English) is one of the longest-standing organisations of linguists and data scientists working with English language corpora. This year’s conference runs from 26–30 May under the theme “A Confluence of Corpus Research in the Age of AI,” bringing together researchers from around the world. The academic programme features full papers, work-in-progress reports, software demonstrations, poster sessions, and plenary talks, complemented by a social programme of a welcome reception, a boat trip, and a gala dinner.
